The Complete Machine Learning Workflow: From Raw Data to Real Business Value
A practical, end-to-end guide to building ML systems that actually deliver results
Introduction: Why Understanding the ML Workflow Matters More Than Ever
Machine learning has moved out of research labs and into the heart of modern business. From the product recommendations on your favourite e-commerce site to the fraud alert that pings your phone seconds after a suspicious transaction, ML is quietly shaping decisions every minute of every day. Yet despite all the buzz, very few people outside of data teams genuinely understand what happens behind the scenes.
Most explanations stop at vague statements like “the algorithm learns from data.” But ML is not magic. It is a carefully engineered workflow involving multiple stages, specialised tools, and a surprising amount of human judgement. Skip a step, and your model fails in production. Get the workflow right, and you unlock a competitive advantage that compounds over time.
In this guide, we will walk through the entire machine learning pipeline as it operates in modern organisations, from the moment raw data is ingested to the moment a business leader makes a smarter decision because of it. Whether you are a product manager trying to scope an AI initiative, an engineer transitioning into ML, or a business executive evaluating where to invest, this article will give you the mental model you need to navigate the ML landscape with confidence.
By the end, you will understand each stage of the pipeline, why it exists, what can go wrong, and how the stages connect to deliver something far more valuable than predictions alone: trustworthy, repeatable, business-grade intelligence.
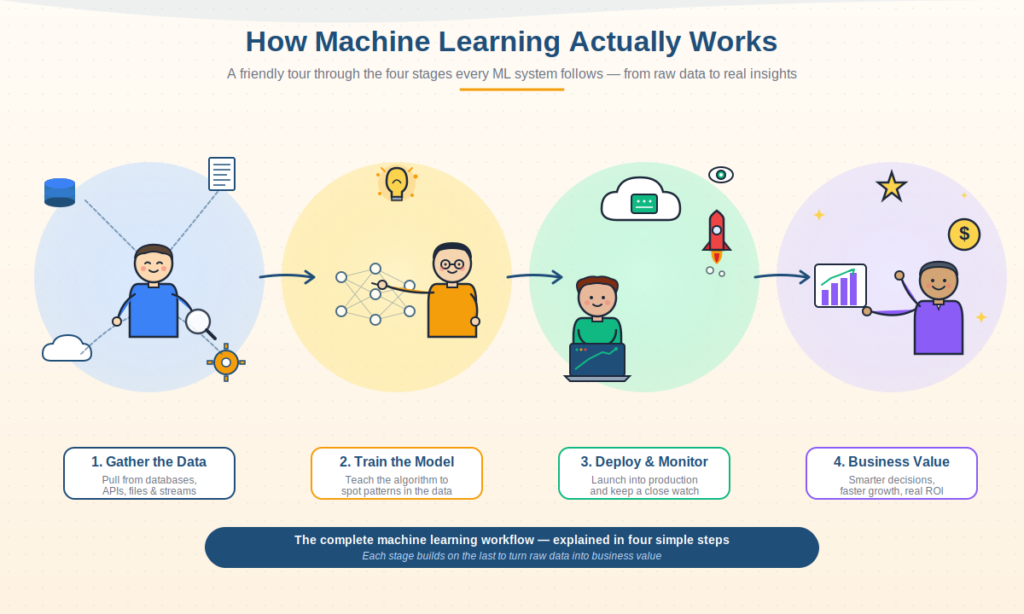
A machine learning model is only as good as the workflow that surrounds it.
Stage 1: Data Ingestion and Sources — The Foundation of Every ML System
Every machine learning journey begins in the same place: data. Without high-quality, diverse, and representative data, even the most sophisticated algorithm becomes a hollow exercise. This is why data ingestion is not just the first step of the pipeline; it is the foundation upon which everything else stands.
Modern ML systems pull from a remarkable variety of sources, and each source brings its own strengths, quirks, and challenges. Understanding these inputs is essential because the quality of decisions a model can make is bounded by the quality of data it sees during training.
The Five Major Data Sources Powering Modern Machine Learning
- Structured data: This is the classic spreadsheet or relational database content—rows and columns with clearly defined fields. Customer records, transaction histories, and inventory tables fall into this category. Structured data is easy to query and analyse, making it the bread and butter of most enterprise ML use cases.
- Unstructured data: Documents, images, audio files, videos, and free-form text fall here. This is where modern deep learning shines, but it also requires far more preprocessing effort. The explosion of multimodal AI has made unstructured data more valuable than ever.
- Live data streams: Real-time feeds from IoT sensors, clickstream logs, financial markets, and social media platforms. Streaming data enables real-time predictions but introduces engineering complexity around latency, ordering, and reliability.
- External API data: Third-party services like weather APIs, currency exchange rates, geolocation lookups, or specialised industry datasets. These enrich your internal data with external context that your model would otherwise lack.
- Historical logs: Archived system records, audit trails, and behavioural logs that often hold patterns invisible at smaller time scales. Historical data is gold for forecasting and trend analysis.
The challenge for ML engineers is not just collecting these sources but unifying them into a coherent feed that downstream stages can rely on. This typically involves data lakes, warehouses, and streaming platforms working in concert, each playing a specific role in the broader data architecture.
Stage 2: Data Preprocessing and Feature Engineering — Where Raw Becomes Ready (Machine Learning)
If raw data is crude oil, then preprocessing is the refinery. Most data scientists will tell you that they spend somewhere between 60 and 80 percent of their time on this single stage, and there is a reason for that: the patterns a model learns are entirely determined by how data is shaped before training.
Preprocessing is where messy reality is transformed into clean, structured input that algorithms can actually digest. Three core activities define this stage, and each one deserves serious attention.
Cleaning and Normalisation
Real-world data is messy. It contains missing values, duplicates, outliers, inconsistent formats, and outright errors. Cleaning involves identifying and resolving these issues so the model does not learn from noise. Normalisation, meanwhile, rescales numerical features to comparable ranges so that one feature does not dominate the others simply because of its units. A salary in rupees and an age in years cannot be treated as equal until they are placed on similar scales.
Feature Extraction
Raw data rarely contains the right inputs for a model in their original form. Feature extraction is the art and science of deriving meaningful signals from raw observations. From a timestamp, you might extract day of the week, hour of the day, or whether it falls on a holiday. From a customer transaction history, you might compute averages, frequencies, and recency metrics. Good feature engineering can make a mediocre algorithm shine; poor feature engineering can sink even the most advanced architecture.
Train, Test, and Validation Splits
Before training begins, the dataset must be carefully divided. A typical approach reserves around 70 percent for training, 15 percent for validation, and 15 percent for testing, though ratios vary based on dataset size and use case. This split is critical because it allows engineers to evaluate how the model performs on data it has never seen before, which is the only honest test of whether learning has actually occurred.
Better data beats better algorithms — almost every single time.
Stage 3: ML Training and Inference Platform — Where the Learning Happens (Machine Learning)
Once data is clean and properly structured, it flows into the heart of the pipeline: the training and inference platform. This is where the actual machine learning takes place, and where the system begins to convert patterns in data into predictive intelligence.
Modern ML platforms are sophisticated environments that handle far more than just running algorithms. They orchestrate compute resources, track experiments, manage model versions, and provide the infrastructure needed to train models reliably at scale.
Model Training
Training is the process by which an algorithm iteratively adjusts its internal parameters to minimise prediction error on the training data. The choice of algorithm—whether linear regression, gradient-boosted trees, deep neural networks, or transformer-based architectures—depends on the problem, the data, and the constraints. There is no universally best algorithm; there is only the best algorithm for the situation at hand.
During training, the model sees thousands or millions of examples and gradually learns the relationships between inputs and outputs. For complex deep learning models, this stage may require specialised hardware like GPUs or TPUs and can run for hours, days, or even weeks.
Hyperparameter Tuning
Every model has hyperparameters—settings that control how learning happens but are not themselves learned from data. Things like learning rate, tree depth, number of layers, or regularisation strength. Choosing the right hyperparameter values can dramatically affect performance. Modern platforms support automated tuning techniques like grid search, random search, Bayesian optimisation, and even neural architecture search, all designed to find optimal settings without manual trial and error.
Cross-Validation
To avoid being misled by a single lucky train-test split, engineers use cross-validation. This technique trains the model on multiple different partitions of the data and averages the results. It produces a more robust estimate of how the model will generalise to new data and helps catch problems like overfitting before they reach production.
Model Evaluation Metrics
How do you know if a model is good? The answer depends on the problem. Classification tasks rely on accuracy, precision, recall, F1 score, and ROC-AUC. Regression problems use measures like mean squared error and R-squared. Ranking and recommendation systems have their own specialised metrics. Choosing the right evaluation metric is itself a strategic decision, because it defines what “good” means to the business.
Stage 4: ML Model Lifecycle and Deployment — From Notebook to Production (Machine Learning)
A model that lives only on a data scientist’s laptop creates exactly zero business value. To deliver real impact, the model must be deployed into a production environment where it can serve predictions to real users or systems in real time. This is the stage where ML engineering truly distinguishes itself from data science.
Deployment, monitoring, and retraining together form the operational backbone of any serious ML system, an emerging discipline often called MLOps.
Deployment: Making the Model Available
Deployment involves packaging the trained model into a form that other systems can use. Most commonly, this means wrapping the model behind an API endpoint, often via containers using technologies like Docker and Kubernetes. The model becomes a service that any application in the company can call. Whether the consumer is a mobile app, a recommendation widget, or an internal dashboard, deployment is what makes consumption possible.
Containerisation also brings the practical benefit of reproducibility. The model behaves the same way whether it runs on a developer’s laptop, a staging server, or a production cluster, because the entire runtime environment is captured in the container image.
Monitoring: Keeping Watch in Production
Once a model is live, the work is not done; it is just beginning. Production models must be monitored continuously for a range of issues. Latency monitoring ensures predictions arrive quickly enough to be useful. Throughput monitoring confirms the system can handle peak load. And, most importantly, prediction monitoring tracks whether the model’s outputs are still accurate and consistent with expectations.
Without robust monitoring, models silently decay. A fraud detection model trained on last year’s patterns may miss this year’s new attack techniques. A demand forecasting model built on pre-pandemic behaviour may produce wildly off forecasts after consumer habits shift. Monitoring catches these problems before they cause real damage.
Re-training: Adapting to Change
When monitoring detects that a model’s performance has degraded, retraining is triggered. This may be scheduled at regular intervals, triggered automatically when drift is detected, or initiated manually by engineers responding to changing business conditions. Modern continuous learning pipelines aim to make this retraining process as seamless as possible, sometimes deploying new model versions multiple times per day.
Stage 5: Model Drift Detection — The Silent Killer of ML Systems (Machine Learning)
Among all the operational concerns in production ML, model drift deserves special attention because it is so often misunderstood. Drift is the gradual degradation of model performance over time as the world changes but the model does not.
There are two main types of drift to watch out for. Data drift occurs when the distribution of input data changes—perhaps your user base has shifted demographically, or new product categories have been introduced. Concept drift happens when the relationship between inputs and outputs changes—what predicted churn last year may no longer predict it today because customer expectations have evolved.
Sophisticated monitoring systems detect drift by comparing recent input distributions against the training distribution, by tracking key model metrics over time, and by maintaining shadow models that can flag when a challenger outperforms the incumbent. When drift is detected, the retraining loop kicks in, and a fresh model is built from updated data.
A model in production is not a finished product — it is a living system that needs constant care.
Stage 6: The Human Side — ML Engineers, Analysts, and Cross-Functional Teams (Machine Learning)
It is tempting to imagine machine learning as a fully automated affair, but the reality is that humans remain deeply involved at every stage. The infographic this article is based on captures this beautifully, showing both ML engineers monitoring the technical system and model performance analysts interpreting the results.
ML Engineers: The Builders and Guardians
ML engineers are responsible for the infrastructure, the pipelines, and the operational health of the system. They write the code that trains models, builds the platforms that serve them, and ensures everything runs reliably at scale. When something breaks at three in the morning, it is the ML engineer who gets paged.
Model Performance Analysts: The Translators
Analysts sit at the intersection of technical and business worlds. They interpret model outputs, generate reports, and translate predictions into actionable insights. They are the ones who answer the question every executive eventually asks: “So what does this mean for our business?”
Strong ML teams treat these roles as complementary rather than separate. Engineers need to understand business context to build the right systems; analysts need enough technical fluency to ask sharp questions. The best organisations build cultures where both skill sets are valued and where collaboration is the default.
Stage 7: Business Value and Reporting — Why We Do All of This (Machine Learning)
Ultimately, no amount of model sophistication matters if the system does not produce business value. The final stage of the ML workflow is where all the technical effort translates into outcomes that decision-makers can actually use.
Predictions and Insights
The most direct output of any ML system is predictions: who will churn, which transaction is fraudulent, what price to set, when equipment will fail. But predictions on their own are not enough. They must be paired with context, confidence levels, and actionable recommendations to truly drive value.
Improved Decision-Making
When predictions are integrated into business processes, they elevate the quality of decisions across the organisation. Marketing teams target the right customers with the right offers. Operations teams allocate resources more efficiently. Finance teams forecast with greater confidence. The compounding effect of better decisions across hundreds of daily situations is what makes ML transformative.
Operational Efficiency
ML automates work that previously required human judgement, freeing teams to focus on higher-value activities. Document classification, claim triage, lead scoring, and quality inspection are just a few examples of processes that can be dramatically accelerated by ML, often at a fraction of the cost of manual workflows.
Model Performance Reports
Finally, transparent reporting closes the loop. Regular performance reports give stakeholders visibility into how models are doing, where they add value, and where they need attention. This transparency builds trust, supports governance, and helps justify continued investment in AI initiatives.
Conclusion: Building ML Systems That Actually Work
The machine learning workflow is not a single technique—it is a chain of carefully coordinated stages, each essential, each demanding its own expertise. From data ingestion through preprocessing, training, evaluation, deployment, monitoring, and reporting, every step contributes to the final outcome. Skip a stage and the chain breaks. Strengthen each stage and the entire system compounds in value.
Organisations that succeed with machine learning are the ones that resist the temptation to view it as a one-time project. Instead, they treat it as an ongoing capability that grows stronger with every iteration. They invest in data quality at the foundation. They build robust training and deployment platforms. They monitor relentlessly and retrain proactively. And they keep human expertise at the centre, where it belongs.
As we move further into an age where AI is woven into nearly every industry, understanding this workflow is no longer optional for technical professionals or business leaders. The companies that master the full lifecycle—not just the algorithms, but the entire ecosystem around them—will be the ones that turn machine learning from a buzzword into a durable competitive advantage.
Whether you are starting your first ML project or scaling an existing one, the principles in this guide remain the same. Respect each stage. Invest in the unglamorous middle stages as heavily as the exciting algorithmic ones. And never forget that the goal is not to build the most clever model—it is to build a system that consistently delivers value to real people solving real problems.
The future belongs to organisations that treat machine learning not as magic, but as engineering.
Key Takeaways
- Data is the foundation. Quality, diversity, and representativeness matter more than algorithmic novelty.
- Preprocessing is where most of the value is created. Invest heavily in cleaning and feature engineering.
- Training is just one stage. Deployment, monitoring, and retraining are equally important for long-term success.
- Drift is inevitable. Build monitoring systems that detect performance degradation before it harms the business.
- Humans remain essential. The best ML systems pair strong engineering with strong business judgement.
- Business value is the ultimate metric. Predictions matter only when they translate into better decisions and outcomes.
Frequently Asked Questions About the Machine Learning Workflow
How long does it take to build a complete machine learning pipeline?
Timelines vary widely based on complexity and organisational maturity. A simple proof of concept on a well-understood dataset might take a few weeks. A production-grade ML pipeline serving millions of predictions per day typically takes anywhere from three to twelve months to build properly, with continuous refinement after launch. Companies that already have strong data infrastructure tend to move significantly faster than those starting from scratch.
What is the difference between machine learning and MLOps?
Machine learning focuses on the algorithms and models themselves: how to train them, evaluate them, and optimise their accuracy. MLOps, on the other hand, focuses on the operational discipline of deploying and maintaining those models in production. Think of ML as the science and MLOps as the engineering practice that makes that science reliable, scalable, and trustworthy in the real world.
Why do ML models fail after deployment?
The most common reasons include data drift, concept drift, infrastructure issues, inadequate monitoring, and mismatch between training data and real-world inputs. Many failures could be prevented with proper observability and a clear retraining strategy. Models also fail when the business problem itself was misunderstood at the start, which is why close collaboration between data teams and business stakeholders matters from day one.
How often should ML models be retrained?
There is no universal answer. Some models benefit from daily or weekly retraining, especially in fast-moving environments like fraud detection or e-commerce personalisation. Others, like medical diagnostic tools, may go months between updates because the underlying patterns are more stable. The right cadence is determined by how quickly the data distribution and business context evolve, combined with how much retraining costs you.
Do I need a huge dataset to build an effective ML model?
Not necessarily. While deep learning models often benefit from massive datasets, many traditional ML algorithms perform admirably with thousands or even hundreds of high-quality examples. In specialised domains, transfer learning and few-shot techniques can produce strong results with relatively little data. Quality, relevance, and labelling accuracy often matter more than raw volume.
What skills should someone develop to work in machine learning?
A solid foundation in statistics, linear algebra, and programming—especially Python—is essential. Beyond that, develop intuition for data, learn to ask sharp questions about model behaviour, and get comfortable with cloud infrastructure and ML platforms. Increasingly, soft skills like communication and business understanding separate good practitioners from great ones, because translating model output into action is where most of the real value is realised.
— End of Article —





One Comment